Science Portal v6
portal
We are delighted to announce the release of Fink Science Portal version 6. While there are no new functionalities this time, there is a major change under the hood that should result in improved performance. Release notes can be found at: https://github.com/astrolabsoftware/fink-science-portal/releases/tag/6.0

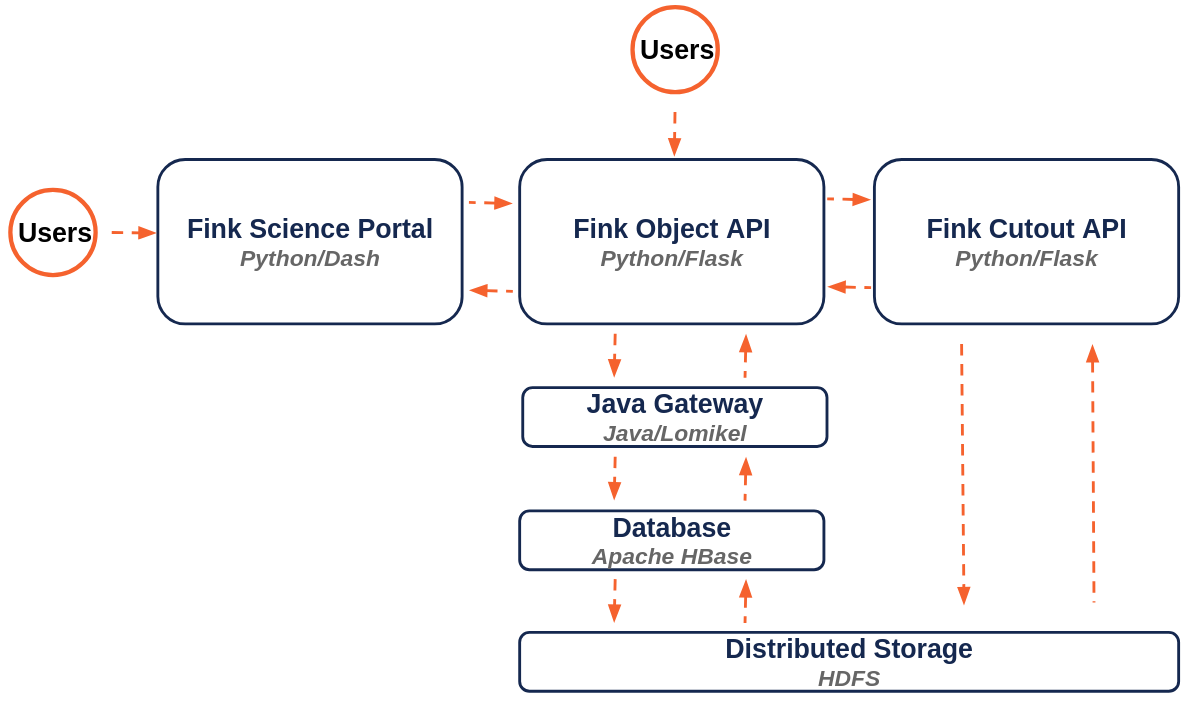
The changes in this new version were driven by the forthcoming Rubin alert stream. To facilitate integration with the new data structures and manage the higher volume of data that will be collected, we redesigned the overall structure. The API is now completely isolated from the frontend, enabling local development. Profilers have been systematically introduced for all endpoint operations, and many parts of the code have been improved. Finally, the new cutout API is now the default method for image data retrieval.
API change
The object API is a Flask application used to access object data stored in tables in Apache HBase. From 2019 to 2024, the development of this API was done in fink-science-portal, and it is now standalone.
New API URL
As part of the transition to a new system for Rubin, the URL to access the API changed from https://fink-portal.org/api/v1/<endpoint> to https://api.fink-portal.org/api/v1/<endpoint>. Both URLs have been valid until January 30, 2025, at which point only https://api.fink-portal.org/api/v1/<endpoint> becomes valid. We encourage all users to update the URL as soon as possible and report any problems. Note that users can access the API documentation at https://api.fink-portal.org where all endpoints are detailed:
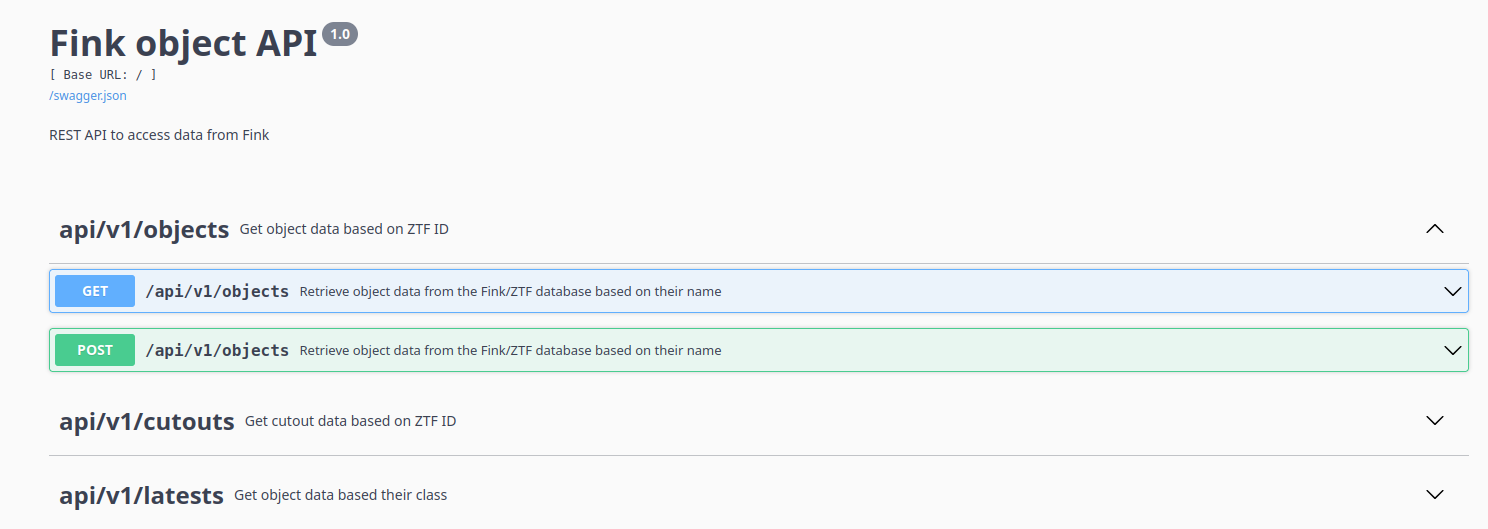
Route changes
Three endpoints have been deprecated:
/api/v1/xmatch/api/v1/random/api/v1/explorer
The endpoint /api/v1/xmatch was a wrapper around /api/v1/conesearch and did not provide any additional performance benefits. To reduce maintenance costs, it has been deprecated. It may be reintroduced if significant performance improvements are achieved. The endpoint /api/v1/random was never used as far as we know. If you were a user of it, please let us know, and it will be re-introduced. The endpoint /api/v1/explorer has been replaced by /api/v1/conesearch. In addition, the endpoint /api/v1/columns has been renamed /api/v1/schema.
See the migration page for more information.
Cutout API
This API (https://github.com/astrolabsoftware/fink-cutout-api) is used internally by Fink web components to retrieve cutouts from the data lake on HDFS. We take advantage of the pyarrow connector to read parquet files to efficiently extract required cutouts from an HDFS block.
Each night, Fink processes alerts and stores them in the datalake as parquet files. Additionally, we transfered data to HBase tables to support various web services. This approach allowed for efficient data exposure once the data is in the tables. However, this has led to numerous issues that outweigh the benefits. One of the most critical tasks during data writing is populating the main table, which includes both lightcurve and cutout data. Frequently, HBase crashes for extended periods—sometimes lasting minutes or even hours—resulting in downtime for all services. Furthermore, cutout data constitutes a significant portion of our storage needs, yet much of it remains rarely accessed.
Since cutouts are already stored in the datalake, if we can develop a quick access method, we can eliminate the need to transfer them to tables. This change would also lead to substantial savings in storage space and costs. This observation has led to the development of this API.
The fundamental mechanism is to store cutout metadata in HBase and leverage the capabilities of pyarrow to read parquet files stored in HDFS. This is (only slightly) slower than accessing cutouts from the HBase table, but it lead to hundreds of TB saved (estimation about 30k EUR saved for the duration of the project!).
The power of the Gateway
The application relies internally on two components, the Fink cutout API (see above), and the Java Gateway. The Java Gateway enables the Flask application to communicate with a JVM using py4j, where the Fink HBase client based on Lomikel is available. This client simplifies the interaction with HBase tables, where Fink aggregated alert data is stored.
Initially, we loaded the client JAR using jpype at the application’s start, sharing the client among all users. This approach caused several issues due to the client’s lack of thread safety. To resolve this, we switched to an isolation mode, where a new client is created for each query instead of reusing a global client.
While this strategy effectively prevents conflicts between sessions, it significantly slows down individual queries. For instance, when using the route api/v1/objects, the overall query time is primarily determined by the time taken to load the client.
Instead of loading the client from scratch in the Python application for each query, we now spawn a JVM once (from outside the Python application), and access Java objects dynamically from the Python application using py4j. This has led to huge speed-up for most queries without the need for cutouts. Note that this technique is heavily inspired from the work in pyspark.
Native Profiling
Inspecting the performance of a web application can be somewhat challenging. While we already have telemetry for Dash components, we are now carefully profiling each application route.