Data transfer at scale (Part 2)
mining
In the previous post, we announced a new service of Fink to explore and transfer historical data at scale from the website https://fink-portal.org/download. And now we are presenting new features to reduce the download time and processing time from the user’s machine.
What’s new
In the recent versions of fink_client (fink_client >= 7.0) we have introduced the functionality of simultaneous downloading from multiple partitions through the implementation of multi-processing technology, which is an approach that takes advantage of modern hardware resources to run multiple tasks in parallel.
By using this strategy, the service is able to simultaneously access different partitions of the data stored in the Kafka server, enabling faster and more efficient transfer. The benefits of this approach are numerous, ranging from optimizing transfer times to making more efficient use of available hardware resources.
How to use
The basic command for downloading data from the Fink Apache Kafka cluster includes the following options :
topic: This is the name of the topic where alerts are loaded.outdir: The directory where the alerts will be stored.partitionby: Specifies how the alerts will be partitioned.
fink_datatransfer \
-topic <topic name> \
-outdir <output directory> \
-partitionby time \
--verbose
In this new version, other options will need to be taken into account:
nconsumers: Determine the number of processes (consumers) to use.
Each process will be assigned a partition in which it will consume all available alerts before being assigned a new, either partially processed or unprocessed partition. For example, with 10 partitions in our topic and 4 consumers, the first consumer will be assigned the first partition, the second consumer the second partition, and so on. Partition 5 will be assigned to the first one to finish retrieving all available alerts in its partition. In our examples, we used a computer with 8 cores. Using a number of consumers greater than 6, the machine started slowing down significantly, and the program began experience freezes and crashes. It becomes unresponsive and can close unexpectedly. Therefore, it is recommended not to use a number of consumers higher than the available number of cores.batchsize: This is the number of alerts downloaded at once by a consumer, and it is set by default to 1000.
fink_datatransfer \
-topic <topic name> \
-outdir <output directory> \
-partitionby time \
-nconsumers 5 \
-batchsize 1000 \
--verbose
Recommendations:
The results obtained from using multiprocessing also depend on the computer’s performance, including the number of CPU and Cores, memory cost, and available bandwidth of the network. Having a large number of consumers or a large batch size is not necessarily the best way to achieve good results.
Nconsumers:
Increasing the number of consumers can reduce the consumption time. However, the greater the number of consumers, the more demanding it is for the computer. Bandwidth should also be taken into account, as it will be shared among all processes, potentially decreasing speed for each additional process.
Here is an example in which we consume all the alerts from the month of July in Lightcurve (approximately 3.9 million alerts with a size of 5.23 GB). The alerts have been fully loaded into the topic before downloading.
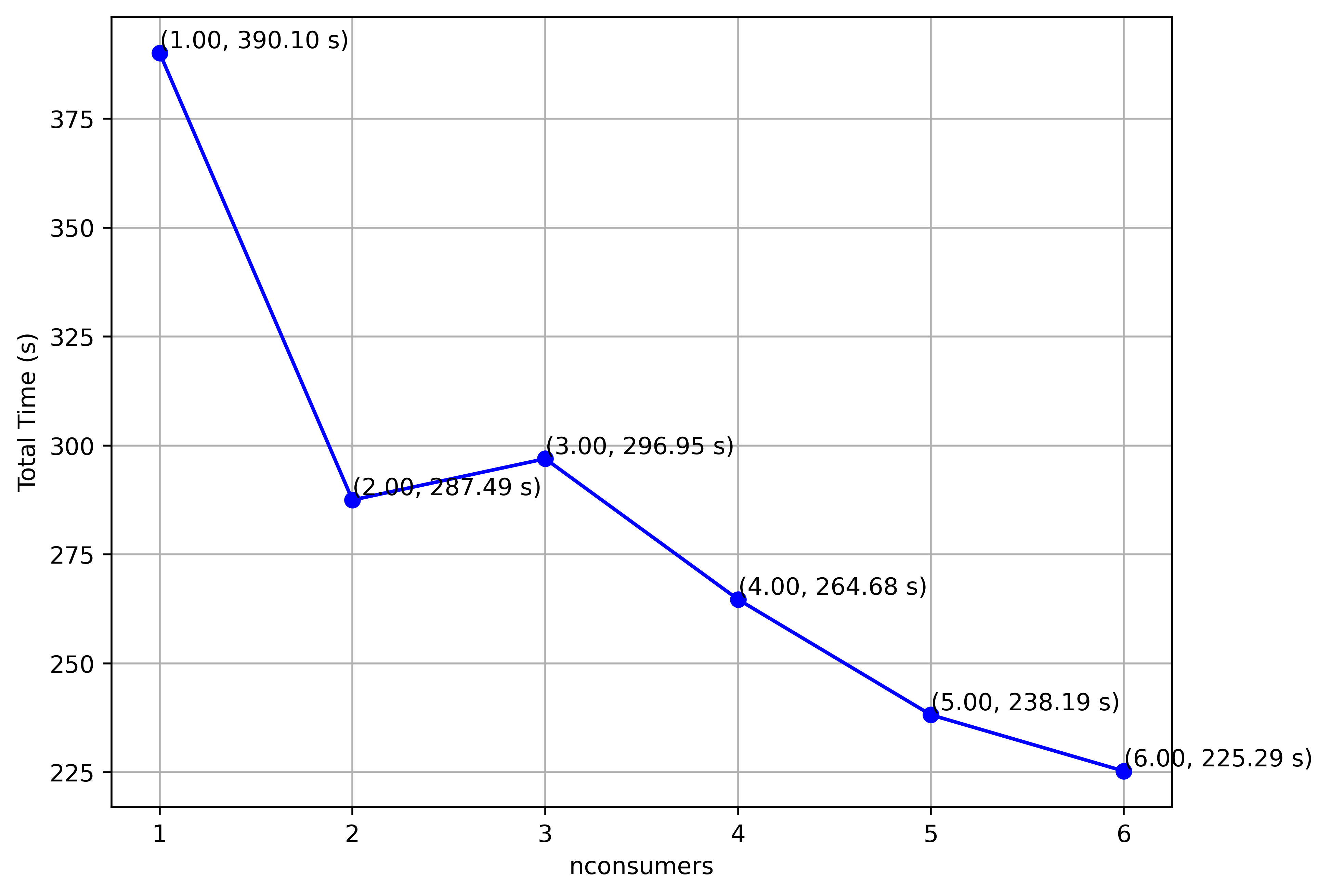
However, it is important to remember that the larger the number of consumers, the higher the chances of the program crashing, and the slower the individual consumer.
Batchsize:
The batch size significantly influences the program’s execution time, especially when the loading of alerts into the topic is complete. In this example with 5 consumers, we observe a significant decrease in execution time as the batch size increases.
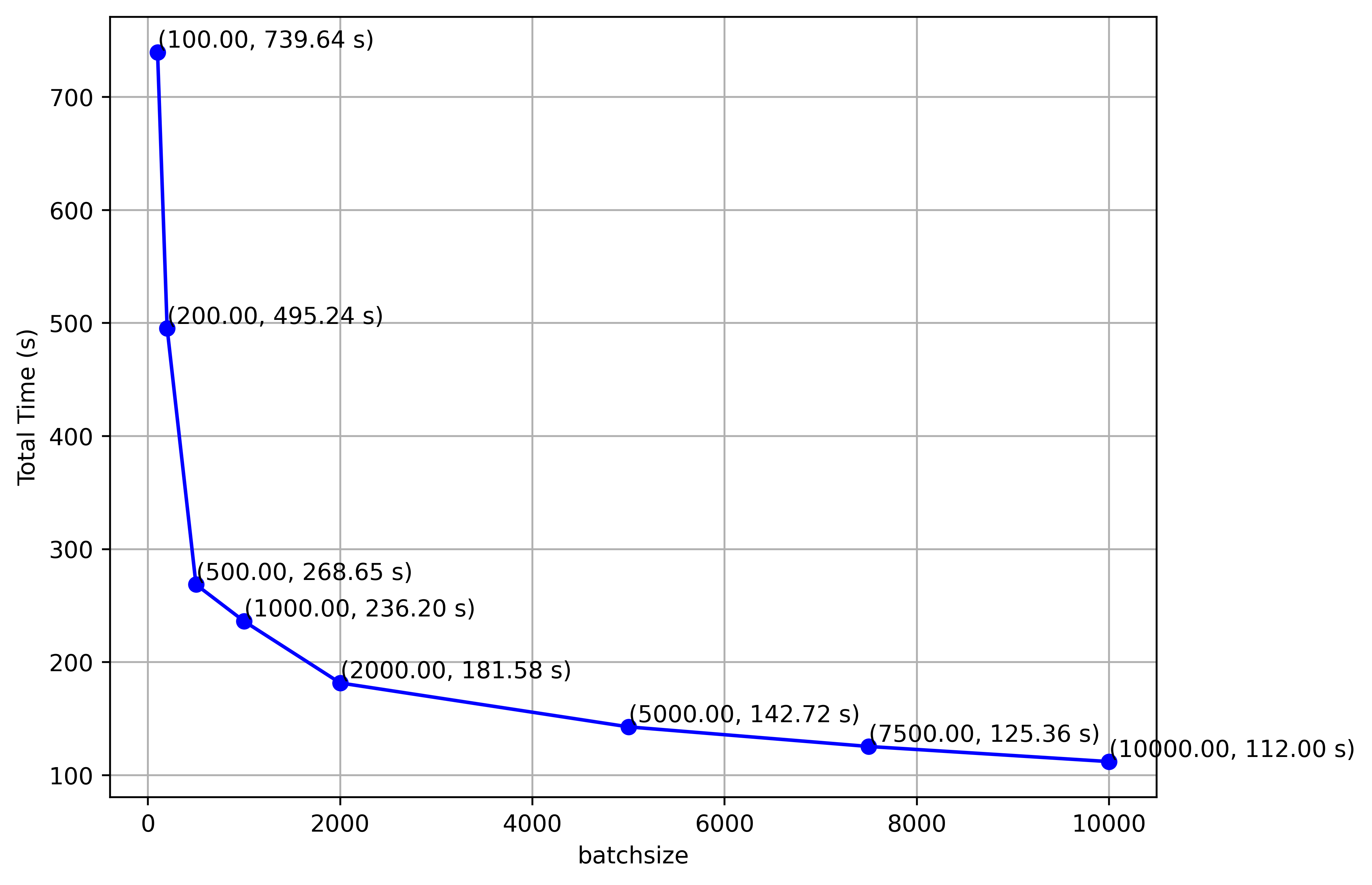
It’s worth noting that a larger batch size leads to a higher memory usage. For a batchsize of 10000 alerts :
- Lightcurve option (assuming 1 alert is about 2 KB) : this would correspond to ~20 MB per batch per process
- Cutouts option (about 40 KB/alert) : this would correspond to ~400 MB per batch per process
- Full packet option (about 55 KB/alert) : corresponding to ~550 MB per batch
Therefore, the batch size should be defined based on the available resources because all programs on the machine can be slowed down, and even unexpectedly closed when there isn’t enough available memory.
Real-time alert reception:
It’s also possible to utilize multiprocessing during real-time alert reception. Each consumer is assigned one partition at a time. After retrieving all available alerts in that partition, it will save the offset of the last retrieved alert in that partition before moving on to another partition. This way, the next consumer to retrieve that partition can continue from that offset.
In general, loading alerts into the Kafka server is slower than receiving them. Therefore, it’s recommended to have a smaller number of consumers than the number of partitions (which is set to 10 in the Fink Kafka cluster). By starting the program around the same time as the beginning of the alert loading and having more than 2 consumers, the program typically finishes a few seconds after the alert loading is complete, which means there is no delay in polling and processing the data.